Introduction
As any programmer or developer would know, with software comes bugs. These bugs may be evident to the developer straight away, or they may be discovered during the initial rounds of software testing. What would happen if some of these bugs were to go undiscovered for a long period of time, even worse what if these bugs were critical and if exploited could potentially hurt the system running them? Cue fuzzing.
What is Fuzzing?
Software fuzzing can be described as the process of feeding a program random input. The program is then observed for crashes. If any of these inputs were to trigger a crash within the software, this would be considered a security flaw.
How does it work?
Intuitively, one could write a program that would generate random input and send this to a target program. This is in fact how early fuzzers worked. While simple to understand there are many limitations to this approach. Often fuzzers use different approaches, let us go over the general steps of fuzzing and take a look at different approaches to them
Steps to fuzzing
We can divide the fuzzing process into four main steps. We explore different types of fuzzers by noting the different approaches they take to each of these steps. These four steps are,
- Value Generation
- Stimulation
- Monitoring
- Feedback
Value Generation
In this segment the inputs that are given to the target program are created. We can generally divide fuzzers into two different generation types
-
Generator Based: The fuzzer does not need an initial input for reference, the values are generated for the target program’s input type. This may occur at random or may use formal grammar.
-
Mutation Based: The fuzzer builds inputs off an initial value provided by the user. Here it may build new inputs by combining two inputs, known as recombination, or making tiny random changes within a single input to create new inputs, known as mutation.
Delivery
Target programs are built for users, not for fuzzers. Due to this, we may face issues when trying to feed the target program fuzzer generated input. This step ensures the target program is running in a suitable environment. The fuzzer also uses filters to ensure that the inputs being sent to the program are valid.
Monitoring
After feeding the target program data we need to monitor how the target program deals with this input. There are different approaches to this, varying in the levels of control we have of the target program.
-
White-Box Fuzzing: Here the target program is a white box. This means that we have complete access to the program’s code, knowledge of its dependencies and their workings. Having complete access to the source code allows us to perform a detailed analysis of the program.
-
Grey-Box Fuzzing: Here we have partial access to the source code of the program, but not full control over the program, its dependencies or execution environment.
-
Black-Box Fuzzing: Under black box fuzzing we have no access to the source code of the program. This is the equivalent of being given just the executable of the program.
Feedback
This step dictates the use of the information we receive from the program during the fuzzing process. Basic fuzzers do not use this information, however, advanced fuzzers use this information to improve the process of fuzzing. However, how would we know whether one input is better than another for fuzzing?
Measuring Fuzzer Performance
Since the goal of a fuzzer is to discover security flaws in a program intuitively, one may think we measure the performance of a fuzzer input by the number of bugs it finds. While this is an important measure, we cannot base the performance of fuzzer inputs off of it.
During the fuzzing process, bugs in the program are encountered very rarely. By measuring the performance of a fuzzer input by whether it finds a bug or not, we aren’t able to assess what parts of input generation should be improved on. So how do we define a metric to measure fuzzer input performance?
The most commonly used measure in modern day fuzzing is code coverage. Code coverage measures how much of the code within the program was executed to process a given input. The idea behind this is that if an input causes more code within the program to run, more code within the program is tested. However this is only applicable in cases where we can measure the code covered, ie, white or grey box approaches.
Blackbox approaches have different approaches to measure input performance. Often external factors are observed, such as change in power consumption, time taken to execute, temperature of the processor, network packets exchanged. All of these may indicate the program is performing intensive / different processing for a given input.
Let us explore a modern day fuzzer type and its architecture, a Coverage-Guided Fuzzer.
Coverage-Guided Fuzzing
Coverage-guided fuzzing is typically a mutation-based grey-box fuzzing method. The performance is measured in code coverage and it is also used to guide changes in the input generation. The process is similar to an evolutionary algorithm.
This may be thought of as biological evolution. The fuzzer starts with a population of inputs. These inputs are run through the program, their performance is measured by a fitness function, in our case this is code coverage. The fitness values for each input in the population allows us to decide which inputs are suitable for us and which need to be discarded.
The inputs that are suitable are mutated via a mix of recombination and mutation. This is the new generation of inputs. The fuzzing cycle is then repeated, this process may be repeated indefinitely until the user stops the fuzzer. While the indepth process may be slightly more complex, this is the general flow of a coverage-guided fuzzer. Below is an image of the detailed process of this type of fuzzer.
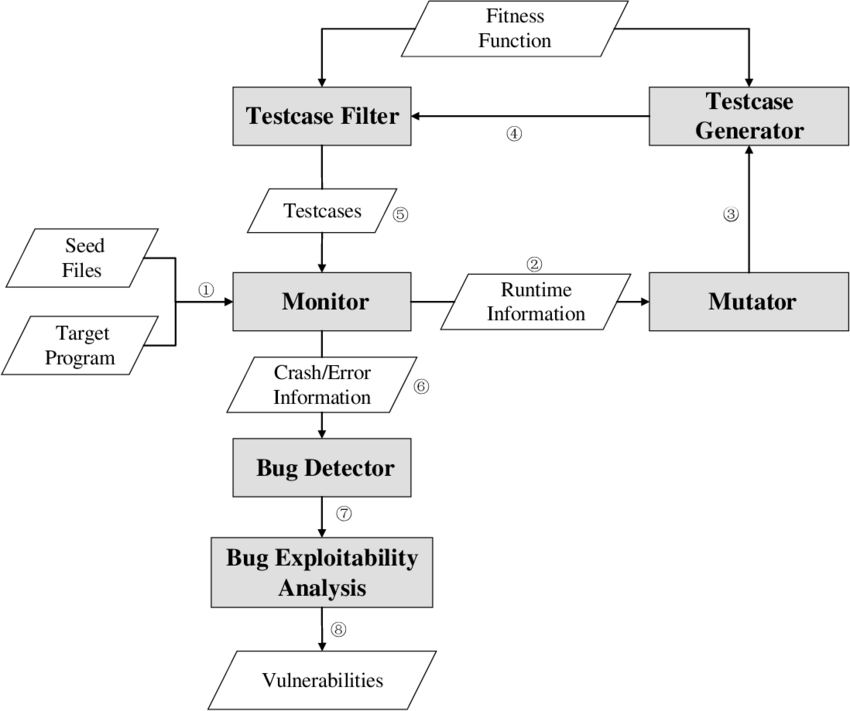
Coverage-Guided Fuzzing
Conclusion
This blog goes over the very basics of fuzzing and introduces some terminology. While I introduced different methods that fuzzers use and how they may be divided. Keep in mind that these divisions are not set in stone and may often be vague, they should just be used as a general flexible guide when working with fuzzers. I may go over a second part of the same topic following a more technical look into the fuzzing process.